
Down the LLM rabbit hole
The race to build makes sense if LLMs can be scaled with more GPUs, but there is good reason to believe the current generation cannot.

Several friends and clients have asked for my thoughts on AI and the mania in both investment and stock valuations. While I have previously noted the shift from free-cashflow financing to debt financing, I held off writing a longer piece until I felt that I had something substantive to contribute. There is already a large amount of excellent commentary out there, from both top down and boots-on-the-ground perspectives1.
And then I stumbled across an interesting interview with Richard Sutton, the “father of reinforcement learning”2 and winner of the 2024 Turing award. Mr Sutton thinks Large Language Models (LLMs) will prove to be a dead-end: albeit in the very specific sense that we will eventually develop something better than LLMs. In his 2019 essay The Bitter Lesson, Sutton argued that architectures which do not scale cleanly with computing power have always lost out to those that do, over time.
If Sutton is correct, this would have profound implications for the current AI race. Current LLMs do not scale efficiently with compute3 - improvements thus far have followed power laws with diminishing returns, and there are other bottle necks such as memory, training data, and human feedback loops. Exponentially more resources are required for each incremental gain - hence the current bun-fight for GPUs, power, land, water and so on.
But while current AI leaders are competing with each other at ever increasing costs, they risk being outflanked by approaches that can overcome constraints on data-sets, human oversight, and so on. Through the lens of Sutton, the question is not will this happen, but when it happens.
In this article I walk through Sutton’s core position, why I agree with him, and the implications for how we should think about the AI mania.
How LLMs Learn: Practice makes performance
Most current LLMs are trained in three stages.
Pre-training: Language patterns
Supervised Fine-Tuning: Following Instructions
Reinforcement Learning: Aligning with user preferences
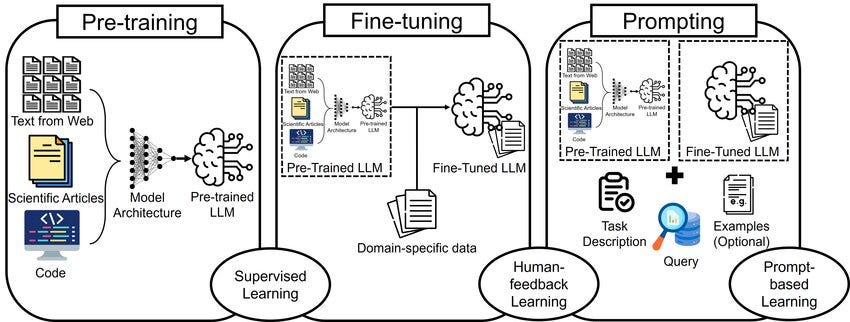
In the first stage, the LLM is fed a huge amount of text and learns, through repetition, how to make reasonable guesses as to the next word in a sequence.
Consider the example: “The capital of France is”.
Depending on your age, the most likely next word is either Paris or “F”. But other words are possible: “to”, or “near”, or “considered”4. The LLM will have a measure of how likely it is that various words continue the fragment “The capital of France is” (or similar fragments) and, in the pre-training phase, the LLM will iteratively update its internal parameters until the distribution of its answers aligns with the data set. Not just for this phrase, but for all phrases in the training data.
The LLM will also learn to use the broader context in which the phrase was found to help guide it. And, like trying to sing along to a song where you half-know the words, this process gets better with more training and when given more context.
Thus, we hit our first non-compute bottle-neck for LLMs - once you have “drunk the internet” generating additional, high-quality training data becomes expensive. And this challenge has grown since LLMs became widely available, as more and more potential training data has been AI-generated. This is intrinsically less valuable than human-generated content and can potentially degrade the training process.
Supervised learning
After pre-training the LLM can respond to a prompt by continuing the conversation. In the next stage it learns to not just continue a string of text, but to respond - to answer a question, analyse a text, engage with a statement.
This is done by using a smaller, carefully (usually human) curated dataset, specifically based on the call-and-respond pattern seen in human conversations (as opposed to human-written text). In this sense, the learning steps are the same as those used in pre-training: the LLM predicts what it believes is the most probable answer, and this is compared to the actual answer in the training data. The LLM then updates its internal model in order to shift its answers towards the pre-determined answer - not for just one prompt/response pair, but in batches.
When thinking about the future of LLMs, this curated data set is another significant bottleneck. There are initiatives to ease it, by using AIs to train other AIs, but at the moment those outputs still need reviewing even if they are not human generated.
Reinforcement Learning from Feedback
In the final phase, the LLM begins to learn what humans like.
In essence this is the same as the preceding steps, except now instead of assessing its answer against a pre-set solution, it generates multiple different answers and human assessors rank their preferences5. Preferred answers are then fed back to the LLM, which adjusts its internal parameters in the usual way to increase the probability that it will generate answers that are perceived as more “helpful”. This is similar to the supervised learning stage, but instead of there being a single target answer for each prompt the feedback is based on a range of possible answers.
This stage, in particular, is where LLMs quickly became polarising once released to the general public - for many subjects there is no single hierarchy of preference. Politics is an obvious example and it’s easy to see how prompts such as “Which US president was the most corrupt?” are likely to divide a userbase, depending on the trainers’ political preferences.
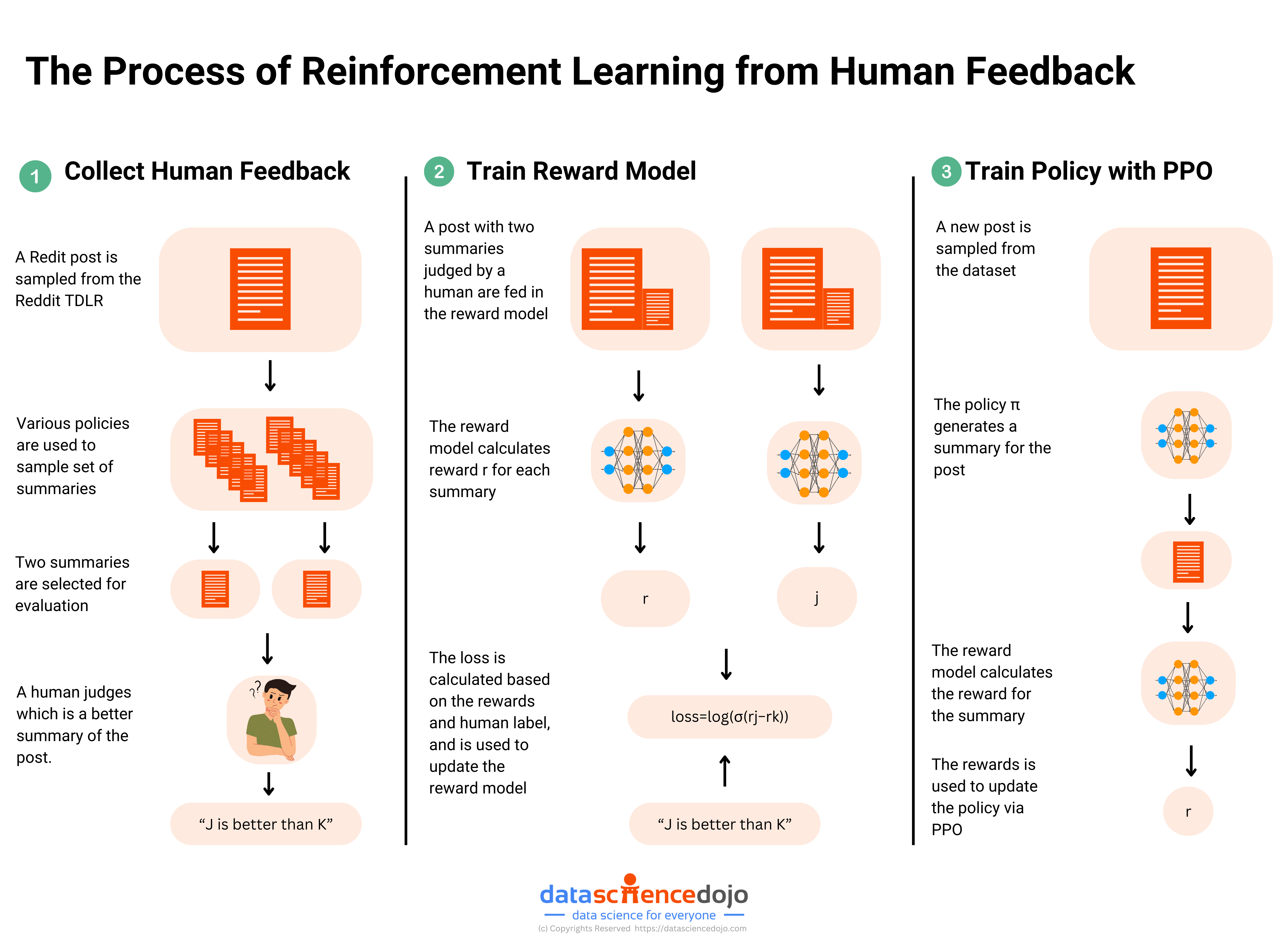
But more fundamentally, this stage opens a window into some of the fundamental short-coming of LLMs - as discussed on the Sutton interview. For example, human interactions have no single, consistent value-maximisation function (goal) - the “best” answer to a question about US Presidents depends on who you are talking to, whether the conversation is public or private, and so on. As humans, we intuitively know that the “best” thing to say depends on who we are talking to, how they are feeling that day, what our desired outcome is, and so on. Humans are complex.
In these situations, LLMs do not solve for “truth” (nor could they) but for likeability - often framed as usefulness. The corporate goal behind many LLMs is to develop AIs that people choose in preference to competition. Some users base this choice on factual accuracy, or usefulness, but many users are likely to select for other characteristics. This, as we will discuss below, is a severe constraint on what LLMs will be able to do even as we scale compute to higher highs.
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.
Richard Sutton, The Bitter Lesson, March 2019
The Bitter Lessons (from Chess and GO)
The Bitter Lesson is a fantastic and, critically, short essay that simply states that over the history of AI/Machine Learning it has, thus far, always been the case that while different methods and strategies have yielded early success, in the end, the winner has always been the approach that best leveraged raw computing power.
In part, this reflects a historical “Moore’s Law” type effect that has seen computing power expand at an exponential rate. As such, methods that have sought to extend the cutting-edge of software intelligence through human-ingenuity have always been over-taken by the growth in computing power and by methods that better leverage it.
Two canonical examples are chess and (more recently) Go.

Early chess engines leveraged human-generated algorithms to evaluate positions. The first computer to beat a reigning world chess Champion (Garry Kasparov) combined human algorithms with “deep search” - playing out millions of possible future moves, to explore as much of the local probability space as possible and select the path that was most likely to win.
But AlphaGo Zero (Go) and AlphaZero (chess) learned not by being told which positions are better, but by playing games against “themselves” (another AI) and working this out themselves. Their training processes were not bound by the set of all games ever recorded (pre-training data), or by a special set of games that exemplified specific strategies (Supervised Fine Tuning), or even by the number of games it could play with humans (Reinforcement Learning from Human Feedback). Because the computer could learn by playing itself, the training data, and the training agents themselves, became themselves scalable with compute.
And because every element of the learning chain scaled, these systems were able to not only overtake human-centric strategies but ultimately to dominate these spaces.
Going down the wrong rabbit hole
Current LLMs do not appear to be capable of transformative applications that might justify the lofty valuations we see in AI stocks. But there is a belief, expressed by CEOs and stock market valuations, that we are close to a breakthrough. This belief justifies a sprint to cross the line first - to bridge the gap with vast amounts of training compute, even if current LLMs do not scale efficiently along this axis.
However, this is far from certain. Adding compute does allow models to be trained more quickly (faster training cycles) - but these gains have power-law relationships, so even the current, GDP-moving levels of investment will only generate incremental progress if past scaling relationships hold. Based on some rough estimates, the hundreds of billions of investments announced could increase training compute by 20-50x for next generation LLMs - but this would only increase performance modestly.
And if these modest improvements are not sufficient for LLMs to generate the required critical breakthrough (as yet undefined), then the perspectives laid in The Bitter Lesson are both deep and profound.
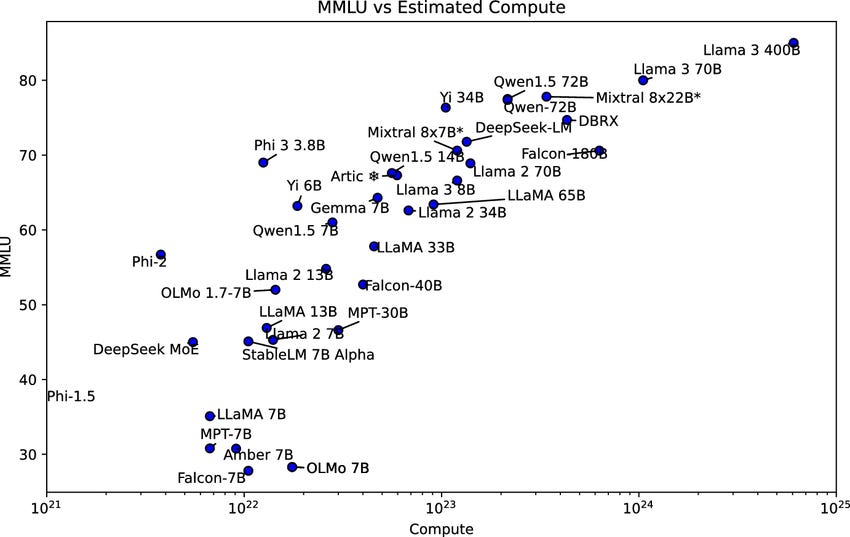
[Note that in this diagram the compute scale is logarithmic - each incremental step requires 10x more compute]
So, the question is: are the current generation of LLMs the equivalent of “Deep Blue”? Destined to be surpassed, but already good enough (or soon to be good enough) to reach a high level of adoption and value generation. Or do the problems that LLMs are trying to solve require an agentic equivalent of AlphaGo? Approaches based on fundamentally different methods: agents that don’t just apply human-derived models (as LLMs do) but derive their own estimates of value.
If we are solving a problem at least as complex as winning at Go, then LLMs are a dead-end. And the problem is likely even more complex than Go: unlike games, human conversations have no defined win-condition. When LLMs have been allowed to talk to each other without objective feedback, they devolve into nonsense because they lack an agenda or goal. It is telling that in areas where “correct” answers can be defined, for example in mathematics, there has been much stronger progress in recent years - a strong hint that the Bitter Lesson is again being learnt when it comes to the more humanistic applications of LLMs.
My position is that LLMs will not make the required break-through on the basis of brute-force investment in compute. If there is a breakthrough it will come from a genuinely new and innovative learning method that is not currently being widely used. Further, based on the Citrini report, I have changed my position somewhat on AI investments, in the sense that I think we may be slightly further into the investment bubble than I had thought. Debt is being issued (most recently Meta) to finance projects, many of which are already under construction.
If these projects fall flat, it will not just be a case of marking down future revenue growth for projects never undertaken (equity re-rating), but there will be real assets to be written down (capital destruction). And the write-downs could be brutal - in some cases Citrini identify that on-site generation turbines and other construction elements are being selected on the basis of what is readily available. This seems likely to (further) accelerate depreciation of these sites in the medium term.
Admittedly, from an equity perspective, the Sutton position tells us nothing about what AI stocks will do in the next six months. But it does put some pointed questions over those 30-year bonds - and that is good enough for me, as a credit guy.
I’ve found the reports from GQG (here and here) and this one from Citrini as particularly interesting and thorough,
A type of Machine Learning where agent learning is driven by a reward function, and the agent explores possible actions to see if they lead to more or less rewards.
Much of the friction occurs after the pre-training stage, as we discuss below.
LLMs actually look at “bits of words” called tokens, but this model is a bit easier conceptually.
Arguably, this is may also be the case in the Supervised Fine Tuning stage, depending on what questions/answers are provided and the trainers curating those examples.